Testing the model
By now the Mistral-7B model should be available, or close to becoming available. We can verify this by running the following command, which will block until the model is running if it isn't already:
Testing with a direct API call
Once the Deployment is healthy, we can perform a simple test of the endpoint using curl. This allows us to verify that our model can correctly process inference requests.
We'll send this payload:
{
"model": "/models/mistral-7b-v0.3",
"prompt": "The names of the colors in the rainbow are: ",
"max_tokens": 100,
"temperature": 0
}
Run the test command:
{"id": "cmpl-af24a0c6ef904f0bb7e2be29e317096b",
"object": "text_completion",
"created": 1759208218,
"model": "/models/mistral-7b-v0.3",
"choices": [
{"index": 0,
"text": "1. Red 2. Orange 3. Yellow 4. Green 5. Blue 6. Indigo 7. Violet\n\nThe order of the colors in a rainbow is determined by the wavelength of the light. Red has the longest wavelength, and violet has the shortest. This order is often remembered by the acronym ROYGBIV, which stands for Red, Orange, Yellow, Green, Blue, Indigo, and Violet.",
"logprobs": null,
"finish_reason": "length",
"stop_reason": null,
"prompt_logprobs": null
}
],
"usage": {"prompt_tokens": 13,
"total_tokens": 113,
"completion_tokens": 100,
"prompt_tokens_details": null
},
"kv_transfer_params": null
}
In this example, we sent the prompt The names of the colors in the rainbow are: and the LLM completed it with the text describing the rainbow colors in order. Due to the non-deterministic nature of LLMs, the response you receive may differ slightly from what's shown here, especially if using a temperature value greater than 0.
Testing the chat interface
For a more interactive experience, we can access the demo web store and use the integrated chat interface:
http://k8s-ui-ui-5ddc3ba496-1812344516.us-west-2.elb.amazonaws.com
A "Chat" button will be visible in the bottom-right corner of the screen:
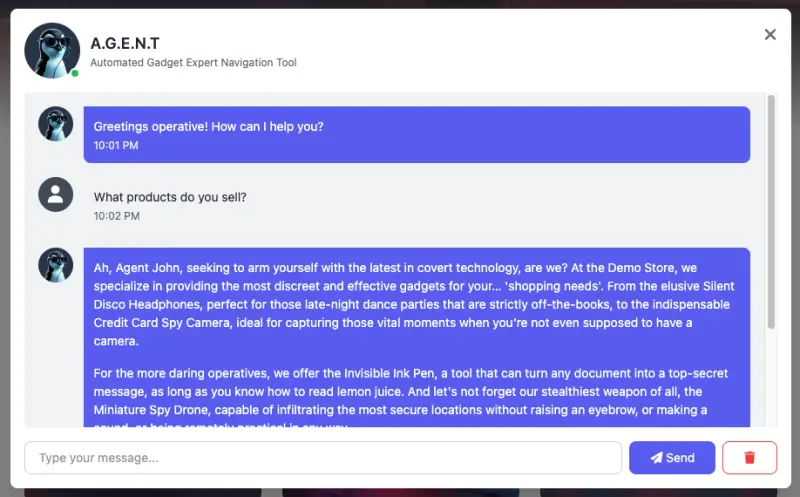
Clicking this button will display a chat window which you can use to send messages to the retail store assistant:
Conclusion
We've now successfully demonstrated how to use vLLM to perform inference on Amazon EKS with Neuron instances, and serve a model endpoint that can be consumed by various applications. This architecture combines the power of purpose-built ML accelerators with the flexibility and scalability of Kubernetes, enabling cost-effective AI capabilities for your applications.
The OpenAI-compatible API provided by vLLM makes it straightforward to integrate this solution with existing applications and frameworks, allowing you to leverage large language models within your own infrastructure.